
¿Qué es el archivo robots.txt y cómo beneficia al SEO de sitios web?
De los googlebots depende que el famoso buscador de Mountain View rastree e indexe el contenido de un sitio web, por lo que interesa allanarles el camino de entrada y facilitarles el trabajo. Sin embargo, no basta con eliminar la metaetiqueta ‘noindex’, porque las arañas rastreadoras de Google son el origen de incontables problemas en el SEO (sí, errare machinum est).
El archivo ‘robots.txt’ nace de la necesidad de orientar a los googlebots en su odisea indexadora, beneficiando de diversas formas el posicionamiento web: evita la inclusión de contenido duplicado, bloquea el rastreo de páginas ocultas, mejora el aprovechamiento del presupuesto de rastreo, etcétera. Debido a la importancia de este protocolo de exclusión, utilizado desde los orígenes de Internet, Google informó en julio de 2019 de su intención de oficializarlo y ponerlo al nivel de los estándares W3C, pues en la actualidad el ‘robots.txt’ se considera un estándar de facto, asumido por el resto de la comunidad web a fuerza de tiempo y uso.
Robots.txt, un protocolo para orientar a los rastreadores de Google
El archivo ‘robots.txt’ se define formalmente como un protocolo de exclusión para robots, es decir, para la legión de crawlers o rastreadores con los que Google investiga páginas internas, URLs, imágenes, enlaces entrantes, etcétera, para su indexación. La finalidad del ‘robots.txt’ es restringir la actividad de los rastreadores en todas aquellas páginas que, por alguna razón, interese mantener fuera de las SERPs. (Pero cuidado, que las etiquetas ‘disallow’ de este protocolo no reemplazan la función de la directiva ‘noindex’, que explicamos en estas técnicas avanzadas para mejorar el SEO).
De este modo, el ‘robots.txt’ cumple una función orientativa y limitante de la actuación de los crawlers, que por su comportamiento a veces gargantuesco pueden enviar al índice de Google cualquier archivo, desde la información de perfiles de registro hasta cadenas de páginas duplicadas en las búsquedas internas. En una palabra, este protocolo de exclusión es SEO friendly, siempre que se le ate corto.
Sintetizando, y en líneas generales, el archivo ‘robots.txt’ es (y no es):
Aclarado qué es el ‘robots.txt’, parece lógico repasar el origen de este protocolo. El ingeniero de software holandés Martijn Koster propuso este archivo como estándar en febrero de 1994 a través de un simple lista de correos electrónicos, después de sufrir un ataque de DDoS a manos del novelista Charles Stross a causa de un comportamiento inadecuado de un crawler.
Con posterioridad este protocolo ha pasado por muchas manos —desarrolladores vinculados a Google, webmasters independientes, etcétera— que durante más de 20 años han perfeccionado su código. Hoy el archivo ‘robots.txt’ es ampliamente utilizado por Google, Bing o Yahoo!, como ayer lo era por Lycos, AltaVista y otros buscadores de la ‘prehistoria’ de la Red.
Un archivo, múltiples utilidades: 4 cosas que el ‘robots.txt’ hace por tu sitio web
Salvando las distancias, un ‘robots.txt’ hace las veces de agente de tráfico, abriendo la circulación en un sentido y restringiéndola en otro. Por supuesto que los conductores temerarios pueden ignorar sus advertencias, pero por lo general su presencia aumentará la seguridad en carretera. Del mismo modo, este protocolo beneficia el posicionamiento SEO de diversas formas, que se desgranarán a continuación:
Optimizar el crawl budget
Que el tiempo es oro lo saben hasta los googlebots, y por ello limitan el tiempo que invierten en analizar los contenidos de un sitio web. Para optimizar este proceso, conocido como presupuesto de rastreo o crawl budget, el uso de ‘robots.txt’ en Google es un poderoso aliado, ya que permite concentrar la atención de los rastreadores en el contenido verdaderamente importante, dejando a un lado las páginas y archivos irrelevantes.
Evitar incurrir en contenido duplicado
El contenido duplicado es una de las principales causas de penalización en motores de búsqueda, por la inflexibilidad del algoritmo Panda con este error, a menudo accidental y al que puede inducir la glotonería de los rastreadores, pues llegan a indexar absolutamente todo. Las directrices del ‘robots.txt’ minimizan este problema, al etiquetar con ‘disallow’ los duplicados inevitables. No obstante, el Centro de Búsqueda de Google alerta de que esta etiqueta no sustituye a ‘noindex’: «No uses un archivo robots.txt para ocultar una página web de los resultados de la Búsqueda de Google, ya que es posible que acabe indexándose aunque no se visite si hay otras páginas que dirigen a ella con texto descriptivo».

Bloquear la indexación de páginas y recursos
‘Bloquear’ es sin duda una palabra inapropiada en este caso, pues la información contenida en el protocolo de exclusión no es vinculante para los crawlers del buscador de Mountain View. Pero en la práctica responde bien al efecto de etiquetar con ‘disallow’ secciones privadas del sitio web que no deberían aparecer en las SERPs, como el acceso de los administradores o el dashboard de los perfiles de usuarios registrados. Inútil será hacerlo, sin embargo, si los buscadores ya han indexado las páginas en cuestión; su utilidad se reduce a las secciones web que aún no hayan sido rastreadas e indexadas.
¿Y para qué más sirve el ‘robots.txt’? De nuevo, el Centro de Búsqueda de Google da la respuesta, pues este archivo ayuda a «gestionar el tráfico de los rastreadores y evitar que aparezcan archivos de imagen, vídeo y audio en los resultados de la Búsqueda de Google. De todas formas, ten en cuenta que no impedirá que otras páginas o usuarios enlacen a tu archivo de imagen, vídeo o audio».
Orientar a los ‘googlebots’ hacia el sitemap
Pese a ser distinto, el archivo ‘robots.txt’ y el sitemap colaboran en cierta medida. Podría suceder, y de hecho sucede, que los rastreadores de Google no encuentren este documento en su ruta habitual (‘www.minegocio.es/sitemap_index.xml’, por ejemplo). En este caso el protocolo ‘robots.txt’ aporta un valioso granito de arena al SEO de la página web, ya que orienta a los motores de búsqueda hacia la ruta del mapa de sitio.
Creando un archivo ‘robots.txt’: estos son sus elementos principales
El directorio de nivel superior del host es el lugar apropiado para alojar al crear un archivo ‘robots.txt’, al que sólo debería accederse con el identificador del puerto y el protocolo adecuados. Su estructura se compone de diversos elementos y etiquetas —user-agent, disallow— que cumplen una función específica, que detallaremos en las siguientes líneas:
User-agent
Con una cuota de mercado del 85,86%, Google monopoliza el tráfico procedente de buscadores, a pesar de que la búsqueda orgánica se ha diversificado en los últimos años, por la introducción de nuevos motores de búsqueda (DuckDuckGo, Baidu) que se han sumado a las antiguas alternativas (Bing, Yahoo!, Yandex). Para especificar a qué buscador queremos transmitir las directrices del ‘robots.txt’ se emplea el código ‘user-agent’, seguido del nombre del crawler en cuestión: bingbot, slurpbot, baiduspider, duckduckbot o sogou spider, entre otros.
Allow
El comando ‘allow’ se utiliza para indicar a los rastreadores que pueden indexar libremente la página en cuestión. Como se observa en el ejemplo de ‘robots.txt’, no es necesario repetir este comando en todas las páginas de una sección o categoría, bastando con mencionarla en su principal: ‘/shop/product’ o ‘/noticias/blog’, por ejemplo.
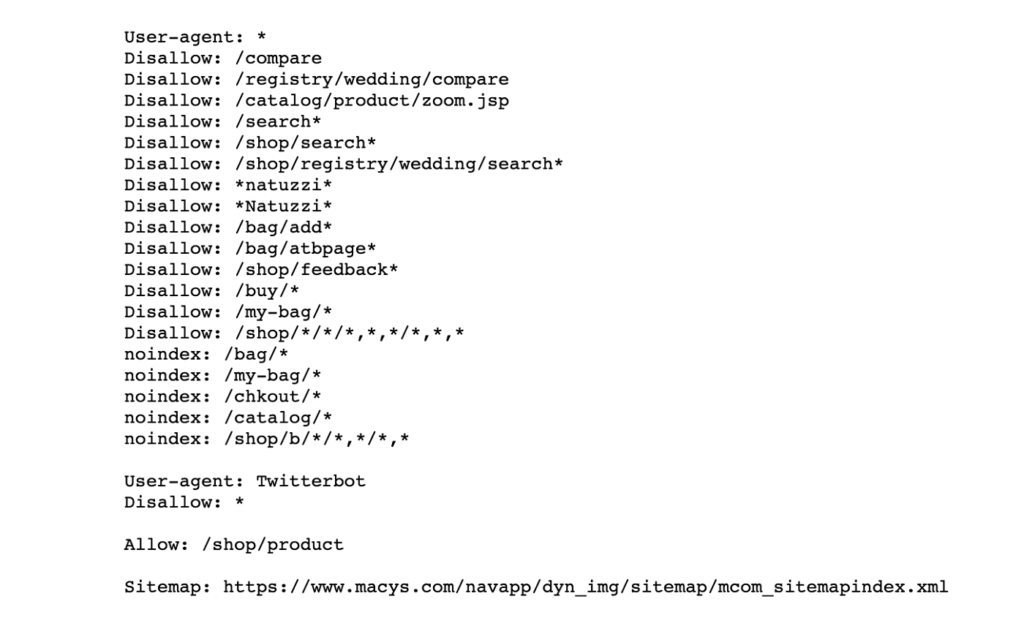
Disallow
Contrariamente a ‘allow’, el comando ‘disallow’ impide a los rastreadores de Google y otros motores de búsqueda el acceso e indexación de los archivos y páginas indicados.
Ruta del sitemap
Como venimos avisando, el archivo ‘robots.txt’ permite clarificar la ruta del mapa de sitio. Para ello se emplea el comando de nombre homónimo, ‘sitemap’, especificando después de dos puntos la URL completa, sin exceptuar el protocolo ‘http’ o ‘https’.
Crawl-delay
Otro comando indispensable para saber cómo configurar el archivo ‘robots.txt’ es ‘crawl-delay’, pensado para determinar los tiempos de acceso y rastreo de cada rastreador, con el fin de prevenir sobrecargas. Un buen ejemplo sería «crawl-delay: 120», que obliga a los diferentes crawlers a esperar este lapso antes de realizar un nuevo sondeo.
Asterisco (*)
El valor del asterisco equivale a una secuencia completa de caracteres y es útil, por tanto, para evitar reiteraciones en el protocolo de exclusión.
Dólar ($)
Para neutralizar el acceso a URLs con una terminación específica, como ‘.jpg’ o ‘.pdf’, existe un comando simbolizado por el dólar estadounidense que realiza esta función. Al igual que el asterisco, pretende ahorrar duplicaciones innecesarias que malgasten el valioso presupuesto de rastreo de los crawlers.
Tabla de contenidos





